本記事の目的
社内のバグ管理システムには数万件規模のチケットが蓄積されており、必要な情報を探し出すのに時間がかかることが問題でした。この問題を解決するため、Agentic RAGの考え方を参考にしたRAGシステムを構築しました。
結果として、質問に対して80%程度の割合で期待する回答が得られるシステムを構築することができました。一方で、構築したRAGシステムの性能評価を通じて、Reflection処理がボトルネックになっているなど、性能改善の余地があることも分かりました。
本記事では、Agentic RAGを参考にした4つの設計要素(計画・ツール使用・自己評価・多段階処理)をどのように実装したか、また評価結果から見えてきた課題と今後の改善方針について共有します。
結果として、質問に対して80%程度の割合で期待する回答が得られるシステムを構築することができました。一方で、構築したRAGシステムの性能評価を通じて、Reflection処理がボトルネックになっているなど、性能改善の余地があることも分かりました。
本記事では、Agentic RAGを参考にした4つの設計要素(計画・ツール使用・自己評価・多段階処理)をどのように実装したか、また評価結果から見えてきた課題と今後の改善方針について共有します。
Agentic RAGとは
Agentic RAGは、自律的なAIエージェントをRAGパイプラインに組み込むアーキテクチャパターンです。
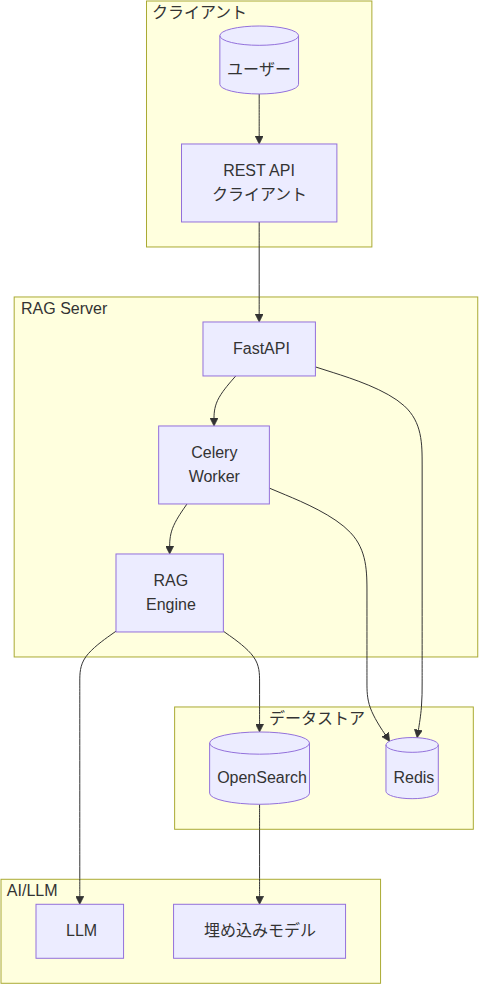
本システムは、Single-Agent型のAgentic RAGを参考に、以下の特性を取り入れています。
| 特性 | 本システムでの実装 |
| 計画(Planning / Routing) | LLMによる質問分類と処理パス決定 |
| ツール使用(Tool Use) | 検索クエリの自動生成とハイブリッド検索 |
| 自己評価(Reflection / Corrective) | 2段階の関連性評価によるフィルタリング |
| 多段階処理(Multi-step) | 分割→統合による大量ドキュメント処理 |
※ 本システムの設計要素は、参考論文(Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG)で挙げられているAgentic Design Patterns(Planning / Tool Use / Reflection / Multi-Agent Collaboration)を基にしています。本システムはSingle-Agent構成のため、Multi-Agent Collaborationの代わりに、実装上の特徴である多段階の統合処理(Synthesis)を取り入れています。
外部仕様
| 入力 | ユーザーからの自然言語による質問(過去の類似不具合やデバッグ手法) 入力例:不具合事象の説明、具体的に解析したい内容、エラーログなど |
| 処理 | 不具合管理システム(数万件のチケット)から質問に対して関連性の高い情報を元に回答を生成 |
| 出力 | 過去の類似不具合やデバッグ手法に関する回答内容(参照元チケットへのリンク付き) |
システム構成
本システムの構成を以下の表に示します。| コンポーネント | 技術 | 選定理由 |
| API | FastAPI | 高速な非同期処理に対応 |
| タスクキュー | Celery + Redis | 長時間処理の非同期実行に対応 |
| RAGフレームワーク | Haystack | 柔軟なパイプライン構築が可能 |
| 検索 | OpenSearch | ベクトル検索とBM25の両方に対応 |
| LLM | Ollama | オンプレミス環境で大規模モデルを運用可能 |
| 埋め込み | nomic-embed-text | 高品質なベクトル表現を生成 |
今回試作したシステム構成図は以下となります。
Agentic RAGを参考にした4つの設計要素(特性)
計画(Planning / Routing)
ユーザーの質問を受け取ると、LLMがまず質問の性質を複数の観点から分類し、最適な処理パスを決定します。
分類の観点:
- 分割して回答可能か
- 特定チケットの参照が必要か
- 追加の検索が必要か
- 回答を統合する必要があるか
この分類結果に基づいて、以下のような処理パスに分岐します:
- 直接参照パス(特定チケットを参照)
- 単純結合パス(統合処理をスキップ)
- 分割回答→統合パス(標準的な処理)
ツール使用(Tool Use)
LLMが検索クエリを自動生成します。ユーザーの質問をそのまま使うのではなく、検索に最適化されたクエリを生成することで、検索精度の向上を図っています。
| クエリ種別 | 生成内容 |
| ベクトル検索用 | 質問の意図を捉えた複数のセンテンス |
| キーワード検索用 | 重要な単語のペア(複数組み) |
各クエリには重要度を付与し、検索結果のスコアリングに使用しています。
自己評価(Reflection / Corrective)
検索結果が質問に対する回答として役立つかを2段階で評価します。この評価プロセスは、前述のAgentic RAGの論文のCorrective RAGの概念に基づいており、不適切な検索結果を除去して回答精度を向上させることを目的としています。
- 1次評価: 粗くフィルタリング
- 2次評価: より厳密にチェック
この2段階評価により、ノイズとなるドキュメントを除去し、回答精度を向上させることを図っています。
多段階処理(Multi-step)
検索で得られた関連チケットが多数ある場合、すべてを一度にLLMへ入力するとコンテキスト長の制限を超える可能性があります。そこで、分割→統合の2段階で回答を生成します。- 分割処理: 関連チケットを小グループに分け、グループごとに質問に対する中間回答を生成
- 統合処理: 各グループの中間回答を統合し、最終回答を作成
データベース構築
RAGシステムの検索精度を高めるため、以下の構成でデータベースを構築しました。データ取得
バグ管理システムから定期的にチケット情報を取得するよう実装しました。取得フォーマットはXML形式を採用し、最終結果だけでなく途中経過のコメントや更新履歴も含めた全文テキストを対象としました。これにより、問題解決に至るまでの議論や試行錯誤の過程も検索可能になります。サマリ生成
取得した各チケットに対して、LLMを用いてサマリを自動生成する仕組みを実装しました。これにより、長文のチケットでも要点を素早く把握できるようになり、検索時のマッチング精度向上にも寄与しています。データ格納
データベースには以下の2種類のデータを格納する構成としました。| データ種別 | 内容 |
| オリジナルデータ | チケットの全文テキスト |
| サマリデータ | LLMが生成した要約 |
メタデータとしてチケットIDを付与することで、検索結果から元のチケットへの参照を可能にしました。
ハイブリッド検索
ベクトル検索とBM25検索を組み合わせ、それぞれの強みを活かす構成としました。| 検索手法 | 特徴 |
| ベクトル検索 | 意味的類似性に強い(「エラー」と「不具合」を関連付け) |
| BM25検索 | キーワードマッチングに強い(正確な型番検索など) |
両検索結果をマージし、重複を除去して統合します。

処理フロー全体
処理フローの全体図は以下の通りとなります。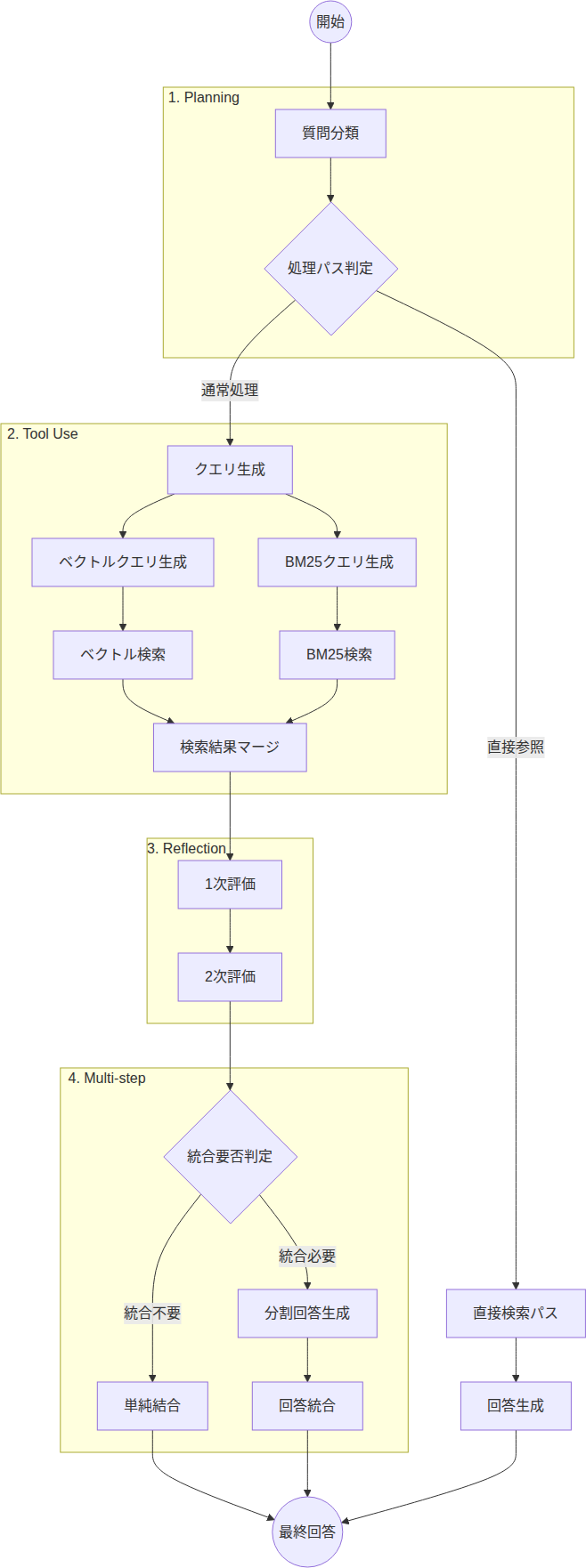
評価結果
ここでは、今回構築したシステムについて、処理時間の内訳と回答精度の観点で評価を行った結果を共有します。
評価環境
| 環境 | CPU | コア/スレッド | メモリ | GPU |
| NVIDIA RTX™ 6000 Ada(HP Z8) | Intel® Xeon® w5-3423 | 12C/24T | 128GB | RTX 6000 Ada × 2 (48GB × 2) |
| NVIDIA® DGX-Spark FE | Arm® Cortex®-X925 + Cortex®-A725 | 20C/20T | 128GB (Unified) | 統合GPU |
※ DGX-Spark FEはCortex®-X925(10コア)+ Cortex®-A725(10コア)
※ DGX-Spark FEはCPU-GPUメモリ共有アーキテクチャ(Unified Memory)
利用LLM: gpt-oss:120b
評価回数: 各環境20回(同一プロンプト使用)
フェーズ毎の時間比率
全体の処理を100%にして、それぞれのフェーズが占める処理時間の割合を表にしました。| Phase | DGX-Spark | RTX6000-Ada |
| 1. Planning | 4% | 5% |
| 2. Tool Use | 2% | 2% |
| 3. Reflection 1次 | 64% | 72% |
| 3. Reflection 2次 | 14% | 8% |
| 4. Multi-step | 17% | 13% |
※現在、Reflection箇所がSingle Agentでの実行となっています。1案としてはMulti Agentにすることで本箇所の高速化ができそうです。
※一例としてRTX6000-Adaの場合、質問から応答を返すまでの時間が平均して8分17秒でした。
比較回答精度
各環境で同一の質問を20回実施し、各回答を人が〇(1点)・△(0.5点)・×(0点)で採点しました。その合計点と平均点は以下の通りです。| テスト環境 | 〇率 | △率 | ×率 |
| RTX6000-Ada | 55% | 35% | 10% |
| DGX-Spark | 75% | 10% | 15% |
総合平均点
| 環境 | 合計点 | 平均点 |
| RTX6000-Ada | 14.5点 | 0.725点 |
| DGX-Spark | 16点 | 0.800点 |
平均点ではDGX-Sparkがやや優位ですが、○+△率で見ると両者はほぼ同等であり、LLMの回答変動も考慮すると両環境に実質的な差はないと評価できます。本結果は参考程度に留めるのが良いと考えます。
今後の課題
本記事では、Agentic RAGの考え方を参考にしたRAGシステムを構築し、バグチケットから情報を抽出し、回答を生成できることを確認しました。今後このRAGシステムを夜間バッチで自動実行できるようにすることを考えているため、パイプライン全体の処理時間(RTX6000-Ada環境で平均8分17秒)は許容範囲内ですが、いくつかの課題が残っています。特に、フェーズ毎の時間比率で示した通り、Reflection 1次処理が全体の64〜72%を占めており、最大のボトルネックとなっています。
確認できた事項
確認できた事項
- Agentic RAGの4つの設計要素(計画・ツール使用・自己評価・多段階処理)の実装
- ハイブリッド検索による検索精度の向上
- RTX6000-Ada環境で平均8分17秒での回答生成
- 約8割の回答精度(○+△率: 85~90%)を達成
- Reflection処理がボトルネック(処理時間の約80%を占有)
- 検索クエリ生成の精度向上の余地
- 同一環境でも再実行により回答内容が変動する(LLMの特性)。
- 環境間の精度差(0.075点)は回間変動幅(0.10~0.15点)より小さく、統計的に有意とは言えない。
- サンプル数(各環境20問)の制約があり、より大規模な評価が必要
次のステップ
現在、Reflection処理はSingle Agent構成で逐次実行しています。この部分をMulti Agent構成に変更し並列化することで、RTX6000-Ada環境では高速化が見込めると考えています。DGX-Spark環境については、アーキテクチャの違いから並列化の効果が異なる可能性があり、別途検証が必要です。
精度面については、評価サンプル数を増やして信頼性を向上させるとともに、回答のばらつきを抑えるためのプロンプト改善も検討していきます。また、データの前処理や検索クエリ生成のチューニングについても検討を進め、進展がありましたら別途記事にまとめる予定です。
精度面については、評価サンプル数を増やして信頼性を向上させるとともに、回答のばらつきを抑えるためのプロンプト改善も検討していきます。また、データの前処理や検索クエリ生成のチューニングについても検討を進め、進展がありましたら別途記事にまとめる予定です。
商標について
※ NVIDIA、RTX、DGXは、NVIDIA Corporationの米国およびその他の国における商標または登録商標です。
※ Intel、Xeonは、Intel Corporationまたはその子会社の米国およびその他の国における商標または登録商標です。
※ Arm、Cortexは、Arm Limited(またはその子会社もしくは関連会社)の米国およびその他の国における登録商標です。
※ その他記載の会社名、製品名は、各社の商標または登録商標です。